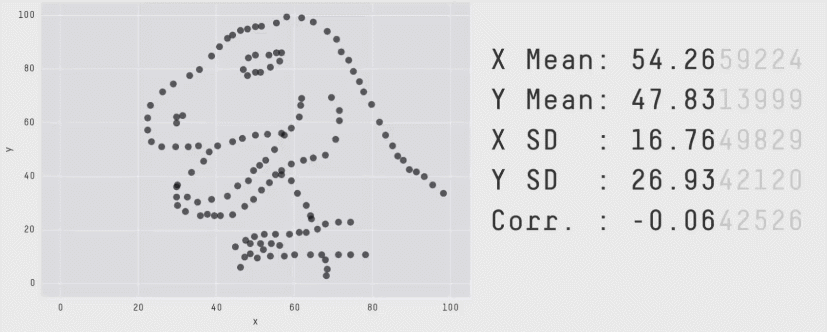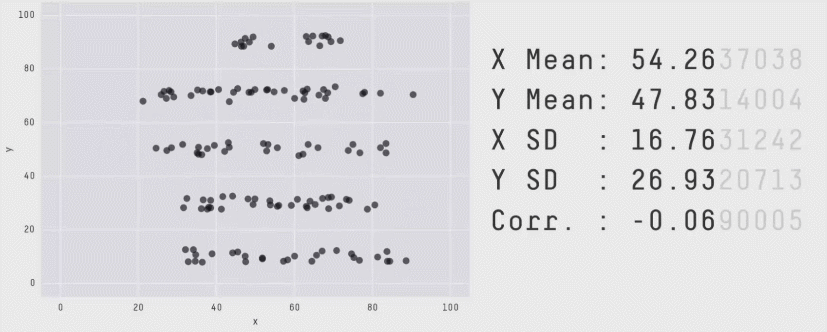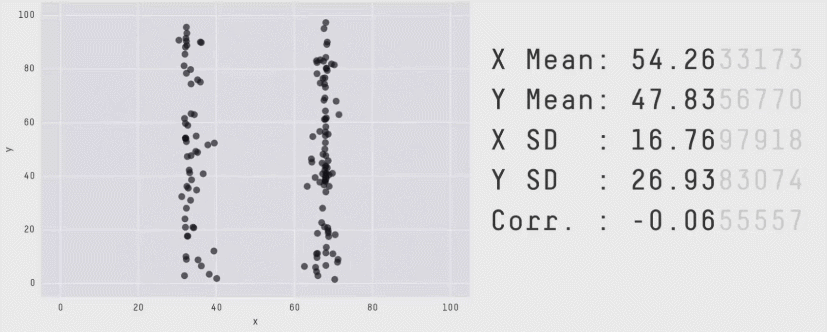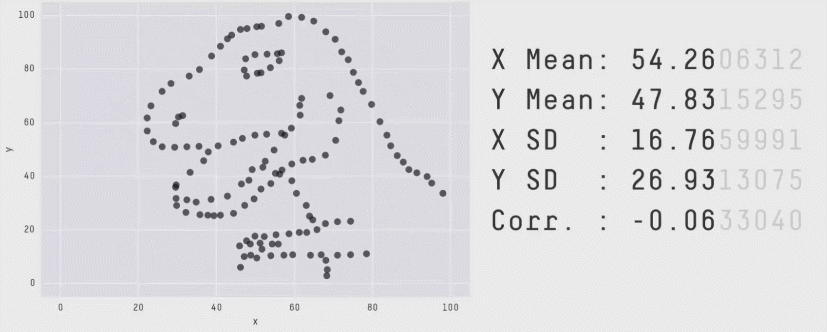
Кожен піднабір містить п’ять статистик, які є (майже) однаковими в кожному випадку:
середнє значення x
середнє значення y
стандартне відхилення x
стандартне відхилення y
та кореляція Пірсона між x та y
Однак діаграми розсіювання показують, що кожен піднабір даних виглядає дуже по-різному. Цей набір даних призначений для того, щоб навчити студентів, що важливо будувати власні графіки, а не покладатися лише на статистичні дані.